mini-spring-course
06|再回首:如何实现一个IoC容器?
你好,我是郭屹。
第一阶段的学习完成啦,你是不是自己也实现出了一个简单可用的IoC容器呢?如果已经完成了,欢迎你把你的实现代码放到评论区,我们一起交流讨论。
我们这一章学的IoC(Inversion of Control)是我们整个MiniSpring框架的基石,也是框架中最核心的一个特性,为了让你更好地掌握这节课的内容,我们对这一整章的内容做一个重点回顾。
IoC重点回顾
IoC是面向对象编程里的一个重要原则,目的是从程序里移出原有的控制权,把控制权交给了容器。IoC容器是一个中心化的地方,负责管理对象,也就是Bean的创建、销毁、依赖注入等操作,让程序变得更加灵活、可扩展、易于维护。
在使用IoC容器时,我们需要先配置容器,包括注册需要管理的对象、配置对象之间的依赖关系以及对象的生命周期等。然后,IoC容器会根据这些配置来动态地创建对象,并把它们注入到需要它们的位置上。当我们使用IoC容器时,需要将对象的配置信息告诉IoC容器,这个过程叫做依赖注入(DI),而IoC容器就是实现依赖注入的工具。因此,理解IoC容器就是理解它是如何管理对象,如何实现DI的过程。
举个例子来说,我们有一个程序需要使用A对象,这个A对象依赖于一个B对象。我们可以把A对象和B对象的创建、配置工作都交给IoC容器来处理。这样,当程序需要使用A对象的时候,IoC容器会自动创建A对象,并将依赖的B对象注入到A对象中,最后返回给程序使用。
我们在课程中是如何一步步实现IoC容器的呢?
我们先是抽象出了Bean的定义,用一个XML进行配置,然后通过一个简单的Factory读取配置,创建bean的实例。这个极简容器只有一两个类,但是实现了bean的读取,这是原始的种子。
然后再扩展Bean,给Bean增加一些属性,如constructor、property和init-method。此时的属性值还是普通数据类型,没有对象。然后我们将属性值扩展到引用另一个Bean,实现依赖注入,同时解决了循环依赖问题。之后通过BeanPostProcessor机制让容器支持注解。
最后我们将BeanFactory扩展成一个体系,并增加应用上下文和容器事件侦听机制,完成一个完整的IoC容器。
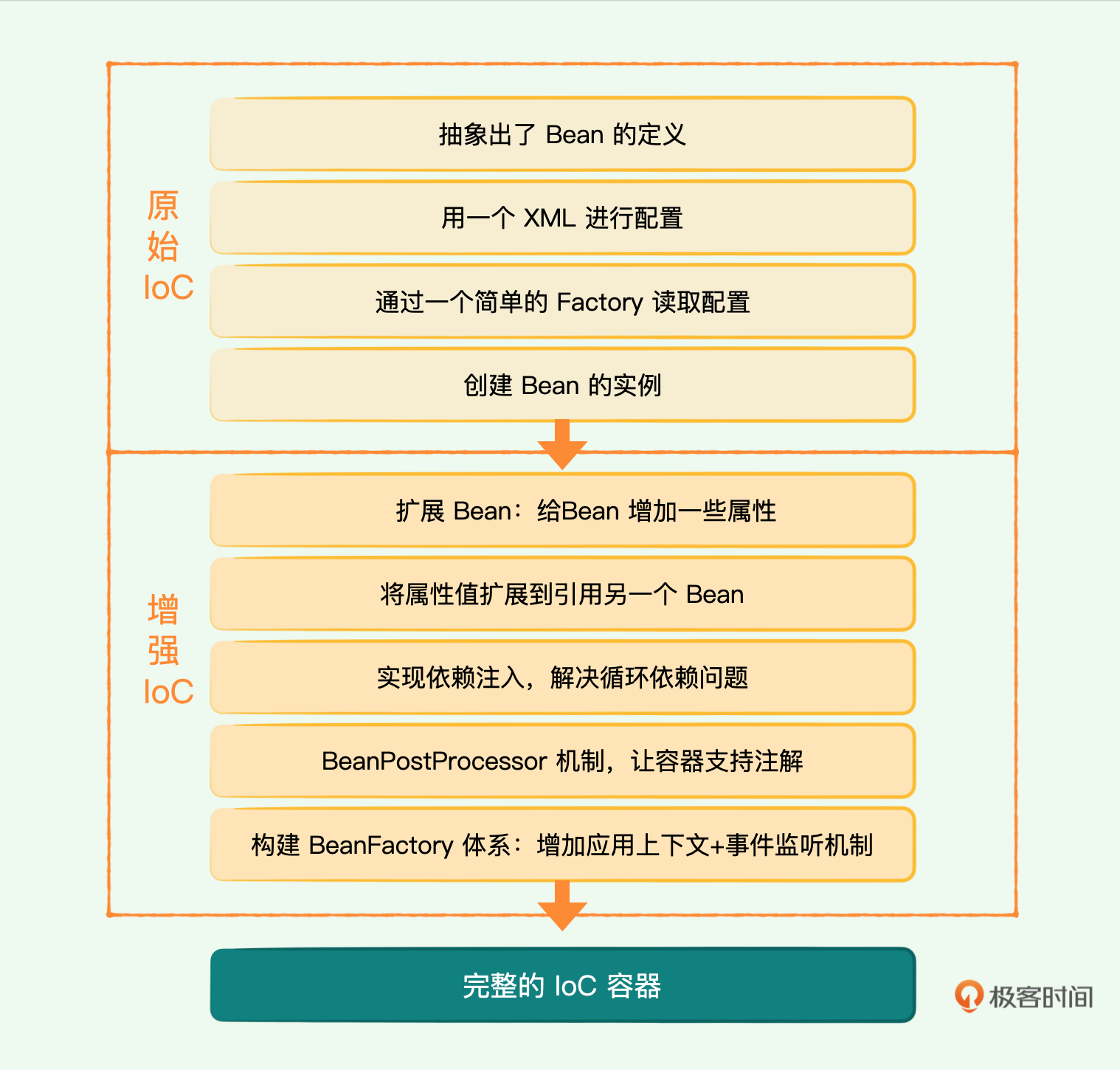
你可以根据这些内容再好好回顾一下这个过程。另外每节课后我都留了一道思考题,你是不是认真做了呢?如果没做的话,我建议你做完再来看答案。
01|原始IoC:如何通过BeanFactory实现原始版本的IoC容器?
思考题
IoC的字面含义是“控制反转”,那么它究竟“反转”了什么?又是怎么体现在代码中的?
参考答案
在传统的程序设计中,当需要一个对象时,我们通常使用new操作符手动创建一个对象,并且在创建对象时需要手动管理对象所依赖的其他对象。但是,在IoC控制反转中,这个过程被翻转了过来,对象的创建和依赖关系的管理被转移到了IoC容器中。
具体来说,在IoC容器中,对象的创建和依赖关系的管理大体分为两个过程。
- 对象实例化:IoC容器负责创建需要使用的对象实例。这意味着如果一个对象需要使用其他对象,IoC容器会自动处理这些对象的创建,并且将它们注入到需要它们的对象中。
- 依赖注入:IoC容器负责把其他对象注入到需要使用这些依赖对象的对象中。这意味着我们不需要显式地在代码中声明依赖关系,IoC容器会自动将依赖注入到对象中,从而解耦了对象之间的关系。
这些过程大大简化了对象创建和依赖关系的管理,使代码更加易于维护和扩展。下面是一个简单的Java代码示例,展示了IoC控制反转在代码中的体现。
public class UserController {
private UserService userService; // 对象不用手动创建,由容器负责创建
public void setUserService(UserService userService) { // 不用手动管理依赖关系,由容器注入
this.userService = userService;
}
public void getUser() {
userService.getUser();
}
}
在上面的示例中,UserController依赖于UserService,但是它并没有手动创建UserService对象,而是通过IoC容器自动注入。这种方式使得代码更加简洁,同时也简化了对象之间的依赖关系。
02|扩展Bean:如何配置constructor、property和init-method?
思考题
你认为通过构造器注入和通过Setter注入有什么异同?它们各自的优缺点是什么?
参考答案
先来说说它们之间的相同之处吧,首先它们都是为了把依赖的对象传递给类或对象,从而在运行时减少或消除对象之间的依赖关系,它们都可以用来注入复杂对象和多个依赖对象。此外Setter注入和构造器注入都可以用来缩小类与依赖对象之间的耦合度,让代码更加灵活、易于维护。
但同时它们之间之间也存在很多的差异。我把它们各自的优缺点整理成了一张表格放到了下面,你可以参考。
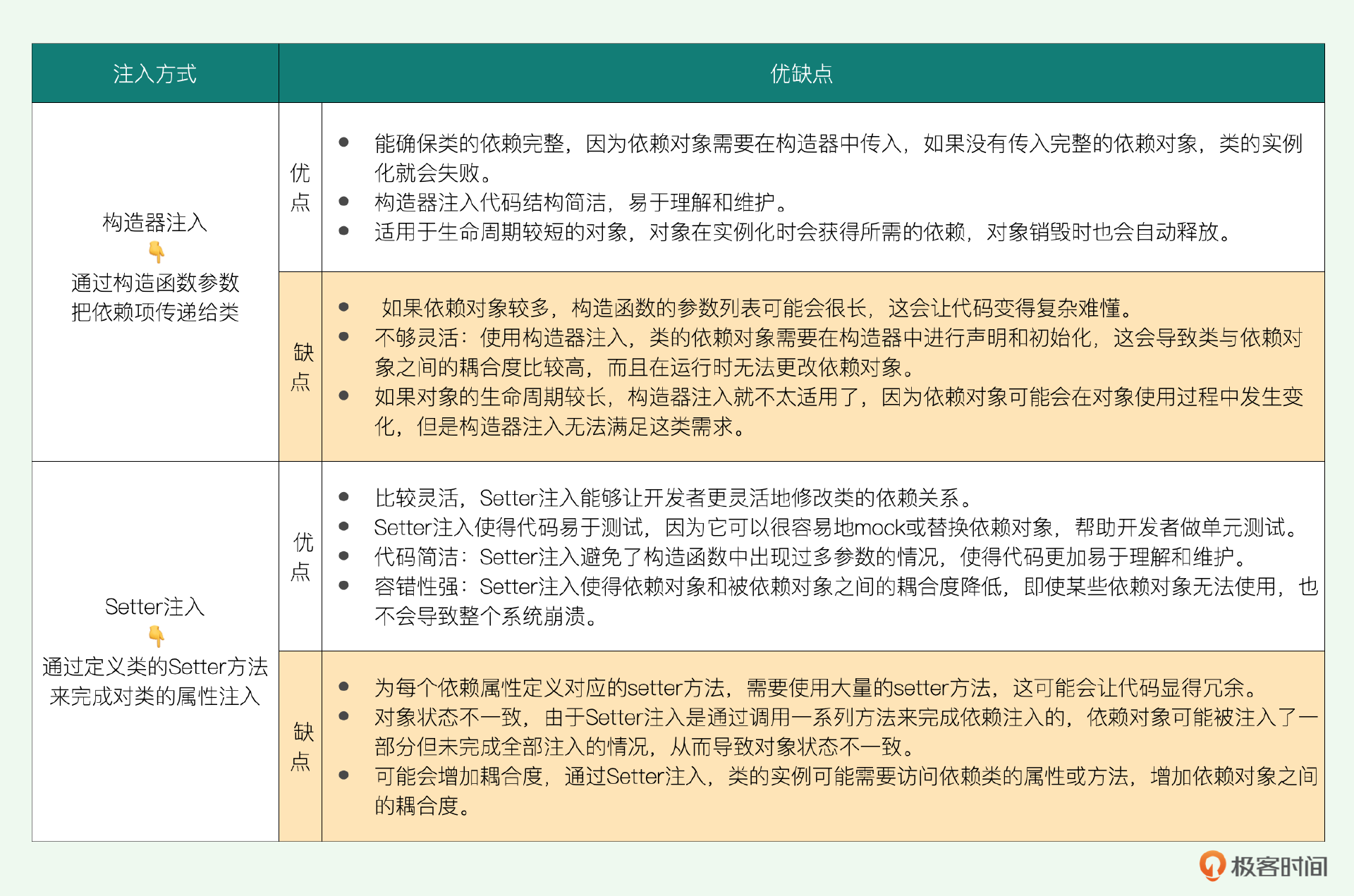
两者之间的优劣,人们有不同的观点,存在持久的争议。Spring团队本身的观点也在变,早期版本他们推荐使用Setter注入,Spring5之后推荐使用构造器注入。当然,我们跟随Spring团队,现在也是建议用构造器注入。
03|依赖注入:如何给Bean注入值并解决循环依赖问题?
思考题
你认为能不能在一个Bean的构造器中注入另一个Bean?
参考答案
可以在一个Bean的构造器中注入另一个Bean。具体的做法就是通过构造器注入或者通过构造器注解方式注入。
方式一:构造器注入
在一个Bean的构造器中注入另一个Bean,可以使用构造器注入的方式。例如:
public class ABean {
private final BBean Bbean;
public ABean(BeanB Bbean) {
this.Bbean = Bbean;
}
// ...
}
public class BBean {
// ...
}
可以看到,上述代码中的 ABean 类的构造器使用了 BBean 类的实例作为参数进行构造的方式,通过这样的方式可以将 BBean 实例注入到 ABean 中。
方式二:构造器注解方式注入
在Spring中,我们也可以通过在Bean的构造器上增加注解来注入另一个Bean,例如:
public class ABean {
private final BBean Bbean;
@Autowired
public ABean(BBean Bbean) {
this.Bbean = Bbean;
}
// ...
}
public class BBean {
// ...
}
在上述代码中,ABean 中的构造器使用了 @Autowired 注解,这个注解可以将 BBean 注入到 ABean 中。
通过这两种方式,我们都可以在一个Bean的构造器中注入另一个Bean,需要根据具体情况来选择合适的方式。通常情况下,通过构造器注入是更优的选择,可以确保依赖项的完全初始化,避免对象状态的污染。
对MiniSpring来讲,只需要做一点改造,在用反射调用Constructor的过程中处理参数的时候增加Bean类型的判断,然后对这个构造器参数再调用一次getBean()就可以了。
当然,我们要注意了。构造器注入是在Bean实例化过程中起作用的,一个Bean没有实例化完成的时候就去实例化另一个Bean,这个时候连“早期的毛胚Bean”都没有,因此解决不了循环依赖的问题。
04|增强IoC容器:如何让我们的Spring支持注解?
思考题
我们实现了Autowired注解,在现有框架中能否支持多个注解?
参考答案
如果这些注解是不同作用的,那么在现有架构中是可以支持多个注解并存的。比如要给某个属性上添加一个@Require注解,表示这个属性不能为空,我们来看下实现的思路。
MiniSpring中,对注解的解释是通过BeanPostProcessor来完成的。我们增加一个RequireAnnotationBeanPostProcessor类,在它的postProcessAfterInitialization()方法中解释这个注解,判断是不是为空,如果为空则抛出BeanException。
然后改写ClassPathXmlApplicationContext类中的registerBeanPostProcessors()方法,将这个新定义的beanpostprocessor注册进去。
beanFactory.addBeanPostProcessor(new
RequireAnnotationBeanPostProcessor());
这样,在getBean()方法中就会在init-method被调用后用到这个RequireAnnotationBeanPostProcessor。
05|实现完整的IoC容器:构建工厂体系并添加容器事件
思考题
我们的容器以单例模式管理所有的bean,那么怎么应对多线程环境?
参考答案
第二节课我们曾经提到过这个问题。这里我们来概括一下。
我们将 singletons 定义为了一个ConcurrentHashMap,而且在实现 registrySingleton 时前面加了一个关键字synchronized。这一切都是为了确保在多线程并发的情况下,我们仍然能安全地实现对单例Bean的管理,无论是单线程还是多线程,我们整个系统里面这个Bean总是唯一的、单例的。——内容来自第 2 课
在单例模式下,容器管理所有的 Bean 时,多线程环境下可能存在线程安全问题。为了避免这种问题,我们可以采取一些措施。
- 避免共享数据
在单例模式下,所有的 Bean 都是单例的,如果 Bean 中维护了共享数据,那么就可能出现线程安全问题。为了避免共享数据带来的问题,我们可以采用一些方法来避免数据共享。例如,在 Bean 中尽量使用方法局部变量而不是成员变量,并且保证方法中不修改成员变量。
- 使用线程安全的数据结构
在单例模式下,如果需要使用一些共享数据的数据结构,建议使用线程安全的数据结构,比如 ConcurrentHashMap 代替 HashMap,使用 CopyOnWriteArrayList 代替 ArrayList 等。这些线程安全的数据结构能够确保在多线程环境下安全地进行并发读写操作。
- 同步
在单例模式下,如果需要操作共享数据,并且不能使用线程安全的数据结构,那么就需要使用同步机制。可以通过 synchronized 关键字来实现同步,也可以使用一些更高级的同步机制,例如 ReentrantLock、ReadWriteLock 等。
需要注意的是,使用同步机制可能会影响系统性能,并且容易出现死锁等问题,所以需要合理使用。
- 使用ThreadLocal
如果我们需要在多线程环境下共享某些数据,但是又想保证数据的线程安全性,可以使用 ThreadLocal 来实现。ThreadLocal 可以保证每个线程都拥有自己独立的数据副本,从而避免多个线程对同一数据进行竞争。
综上所述,在单例模式下,为了避免多线程环境下的线程安全问题,我们需要做好线程安全的设计工作,避免共享数据,选用线程安全的数据结构,正确使用同步机制,以及使用ThreadLocal等方法保证数据的线程安全性。