mini-spring-course
01|原始IoC:如何通过BeanFactory实现原始版本的IoC容器?
你好,我是郭屹,从今天开始我们来学习手写MiniSpring。
这一章,我们将从一个最简单的程序开始,一步步堆积演化,最后实现Spring这一庞大框架的核心部分。这节课,我们就来构造第一个程序,也是最简单的一个程序,将最原始的IoC概念融入我们的框架之中, 我们就用这个原始的IoC容器来管理一个Bean。 不过要说的是,它虽然原始,却也是一个可以运行的IoC容器。
IoC容器
如果你使用过Spring或者了解Spring框架,肯定会对IoC容器有所耳闻。它的意思是使用Bean容器管理一个个的Bean,最简单的Bean就是一个Java的业务对象。在Java中,创建一个对象最简单的方法就是使用 new 关键字。IoC容器,也就是 BeanFactory,存在的意义就是将创建对象与使用对象的业务代码解耦,让业务开发人员无需关注底层对象(Bean)的构建和生命周期管理,专注于业务开发。
那我们可以先想一想,怎样实现Bean的管理呢?我建议你不要直接去参考Spring的实现,那是大树长成之后的模样,复杂而庞大,令人生畏。
作为一颗种子,它其实可以非常原始、非常简单。实际上我们只需要几个简单的部件:我们用一个部件来对应Bean内存的映像,一个定义在外面的Bean在内存中总是需要有一个映像的;一个XML reader 负责从外部XML文件获取Bean的配置,也就是说这些Bean是怎么声明的,我们可以写在一个外部文件里,然后我们用XML reader从外部文件中读取进来;我们还需要一个反射部件,负责加载Bean Class并且创建这个实例;创建实例之后,我们用一个Map来保存Bean的实例;最后我们提供一个getBean() 方法供外部使用。我们这个IoC容器就做好了。
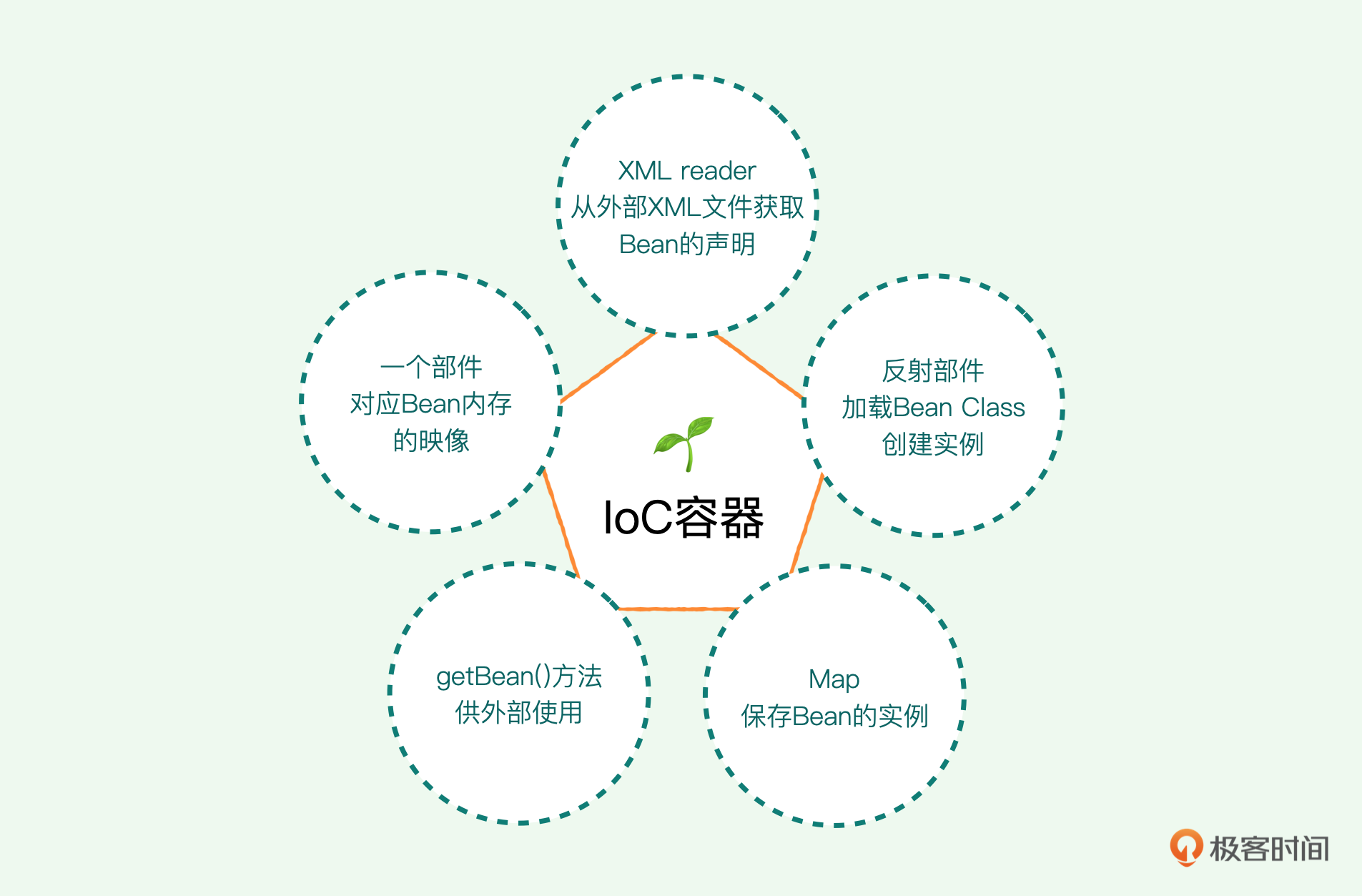
好,接下来我们一步步来构造。
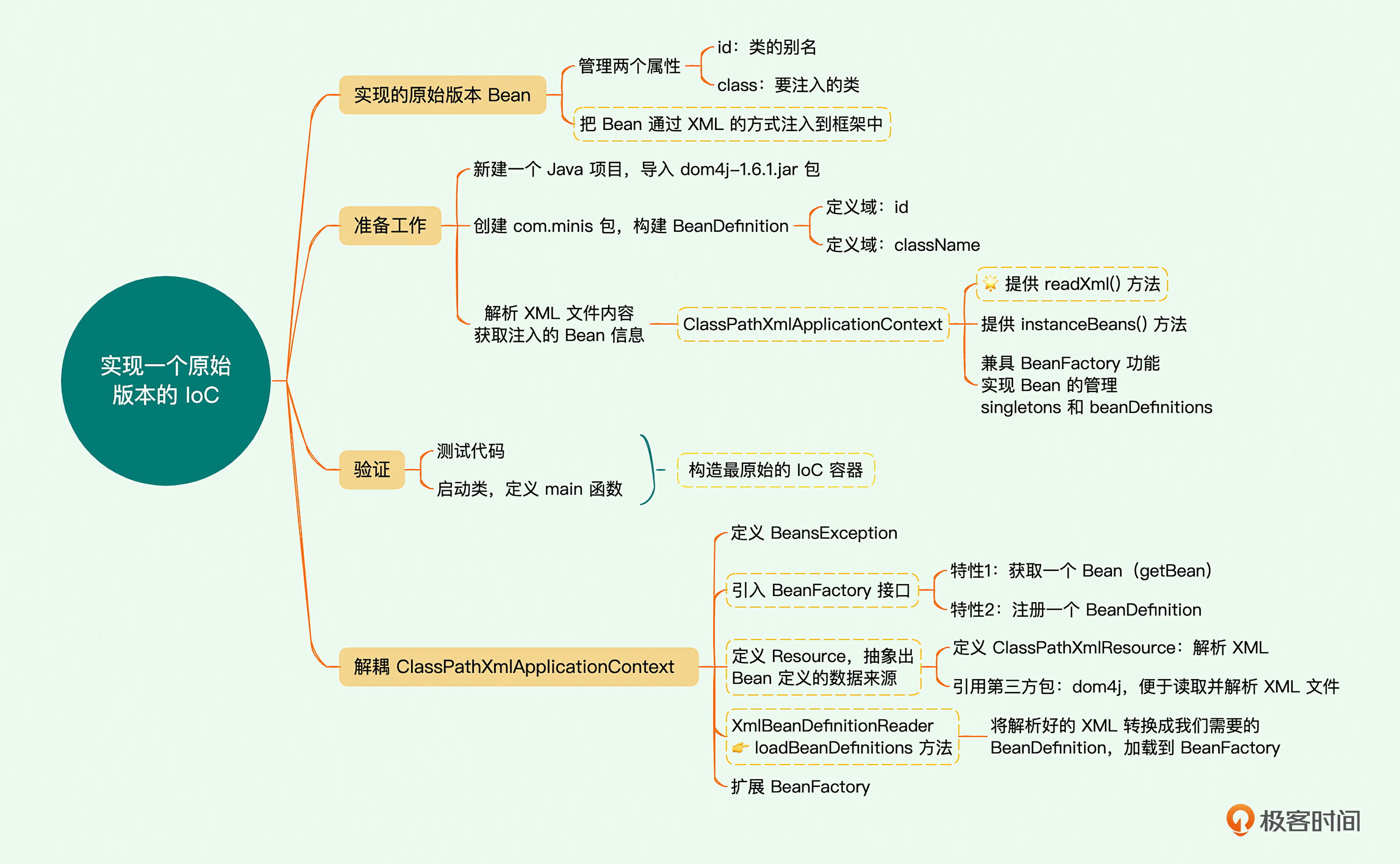
实现一个原始版本的IoC容器
对于现在要着手实现的原始版本Bean,我们先只管理两个属性: id与class。其中,class表示要注入的类,而id则是给这个要注入的类一个别名,它可以简化记忆的成本。我们要做的是把Bean通过XML的方式注入到框架中,你可以看一下XML的配置。
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<bean id = "xxxid" class = "com.minis.xxxclass"></bean>
</beans>
接下来我们要做一些准备工作。首先,新建一个Java项目,导入dom4j-1.6.1.jar包。这里导入的dom4j包封装了许多操作XML文件的方法,有助于我们快速处理XML文件中的各种属性,这样就不需要我们自己再写一个XML的解析工具了,同时它也为我们后续处理依托于XML注入的Bean提供了便利。
另外要说明的是,我们写MiniSpring是为了学习Spring框架,所以我们会尽量少地去依赖第三方包,多自己动手,以原始社会刀耕火种的方式写程序,这可以让我们彻底地理解底层原理。希望你能够跟我一起动手,毕竟编程说到底是一个手艺活,要想提高编程水平,唯一的方法就是动手去写。只要不断学,不断想,不断做,就能大有成效。
构建BeanDefinition
好了,在有了第一个Java项目后,我们创建com.minis包,我们所有的程序都是放在这个包下的。在这个包下构建第一个类,对应Bean的定义,命名为BeanDefinition。我们在这个类里面定义两个最简单的域:id与className。你可以看一下相关代码。
public class BeanDefinition {
private String id;
private String className;
public BeanDefinition(String id, String className) {
this.id = id;
this.className = className;
}
//省略getter和setter
可以看到,这段代码为这样一个Bean提供了全参数的构造方法,也提供了基本的getter和setter方法,方便我们获取域的值以及对域里的值赋值。
实现ClassPathXmlApplicationContext
接下来,我们假定已经存在一个用于注入Bean的XML文件。那我们要做的自然是,按照一定的规则将这个XML文件的内容解析出来,获取Bean的配置信息。我们的第二个类ClassPathXmlApplicationContext就可以做到这一点。通过这个类的名字也可以看出,它的作用是解析某个路径下的XML来构建应用上下文。让我们来看看如何初步实现这个类。
public class ClassPathXmlApplicationContext {
private List<BeanDefinition> beanDefinitions = new ArrayList<>();
private Map<String, Object> singletons = new HashMap<>();
//构造器获取外部配置,解析出Bean的定义,形成内存映像
public ClassPathXmlApplicationContext(String fileName) {
this.readXml(fileName);
this.instanceBeans();
}
private void readXml(String fileName) {
SAXReader saxReader = new SAXReader();
try {
URL xmlPath =
this.getClass().getClassLoader().getResource(fileName);
Document document = saxReader.read(xmlPath);
Element rootElement = document.getRootElement();
//对配置文件中的每一个<bean>,进行处理
for (Element element : (List<Element>) rootElement.elements()) {
//获取Bean的基本信息
String beanID = element.attributeValue("id");
String beanClassName = element.attributeValue("class");
BeanDefinition beanDefinition = new BeanDefinition(beanID,
beanClassName);
//将Bean的定义存放到beanDefinitions
beanDefinitions.add(beanDefinition);
}
}
}
//利用反射创建Bean实例,并存储在singletons中
private void instanceBeans() {
for (BeanDefinition beanDefinition : beanDefinitions) {
try {
singletons.put(beanDefinition.getId(),
Class.forName(beanDefinition.getClassName()).newInstance());
}
}
}
//这是对外的一个方法,让外部程序从容器中获取Bean实例,会逐步演化成核心方法
public Object getBean(String beanName) {
return singletons.get(beanName);
}
}
由上面这一段代码可以看出,ClassPathXmlApplicationContext定义了唯一的构造函数,构造函数里会做两件事:一是提供一个readXml()方法,通过传入的文件路径,也就是XML文件的全路径名,来获取XML内的信息,二是提供一个instanceBeans()方法,根据读取到的信息实例化Bean。接下来让我们看看,readXml和instanceBeans这两个方法分别做了什么。
首先来看readXML,这也是我们解析Bean的核心方法,因为配置在XML内的Bean信息都是文本信息,需要解析之后变成内存结构才能注入到容器中。该方法最开始创建了SAXReader对象,这个对象是dom4j包内提供的。随后,它通过传入的fileName,也就是定义的XML名字,获取根元素,也就是XML里最外层的标签。然后它循环遍历标签中的属性,通过 element.attributeValue("id") 和 element.attributeValue("class") 拿到配置信息,接着用这些配置信息构建BeanDefinition对象,然后把BeanDefinition对象加入到BeanDefinitions列表中,这个地方就保存了所有Bean的定义。
接下来,我们看看instanceBeans方法实现的功能:实例化一个Bean。因为BeanDefinitions存储的BeanDefinition的class只是一个类的全名,所以我们现在需要将这个名字转换成一个具体的类。我们可以通过Java里的反射机制,也就是Class.forName将一个类的名字转化成一个实际存在的类,转成这个类之后,我们把它放到singletons这个Map里,构建 ID 与实际类的映射关系。
到这里,我们就把XML文件中的Bean信息注入到了容器中。你可能会问,我到现在都没看到BeanFactory呀,是不是还没实现完?
其实不是的,目前的ClassPathXmlApplicationContext兼具了BeanFactory的功能,它通过singletons和beanDefinitions初步实现了Bean的管理,其实这也是Spring本身的做法。后面我会进一步扩展的时候,会分离这两部分功能,来剥离出一个独立的BeanFactory。
验证功能
现在,我们已经实现了第一个管理Bean的容器,但还要验证一下我们的功能是不是真的实现了。下面我们就编写一下测试代码。在com.minis目录下,新增test包。你可以看一下相关的测试代码。
public interface AService {
void sayHello();
}
这里,我们定义了一个sayHello接口,该接口的实现是在控制台打印出“a service 1 say hello”这句话。
public class AServiceImpl implements AService {
public void sayHello() {
System.out.println("a service 1 say hello");
}
}
我们将XML文件命名为beans.xml,注入AServiceImpl类,起个别名,为aservice。
<?xml version="1.0" encoding="UTF-8" ?>
<beans>
<bean id = "aservice" class = "com.minis.test.AServiceImpl"></bean>
</beans>
除了测试代码,我们还需要启动类,定义main函数。
public class Test1 {
public static void main(String[] args) {
ClassPathXmlApplicationContext ctx = new
ClassPathXmlApplicationContext("beans.xml");
AService aService = (AService)ctx.getBean("aservice");
aService.sayHello();
}
}
在启动函数中可以看到,我们构建了ClassPathXmlApplicationContext,传入文件名为“beans.xml”,也就是我们在测试代码中定义的XML文件名。随后我们通过getBean方法,获取注入到singletons里的这个类AService。aService在这儿是AService接口类型,其底层实现是AServiceImpl,这样再调用AServiceImpl类中的sayHello方法,就可以在控制台打印出“a service 1 say hello”这一句话。
到这里,我们已经成功地构造了一个最简单的程序: 最原始的IoC容器。在这个过程中我们引入了BeanDefinition的概念,也实现了一个应用的上下文ClassPathXmlApplicationContext,从外部的XML文件中获取文件信息。只用了很少的步骤就实现了IoC容器对Bean的管理,后续就不再需要我们手动地初始化这些Java对象了。
解耦ClassPathXmlApplicationContext
但是我们也可以看到,这时的 ClassPathXmlApplicationContext 承担了太多的功能,这并不符合我们常说的对象单一功能的原则。因此,我们需要做的优化扩展工作也就呼之欲出了:分解这个类,主要工作就是两个部分,一是提出一个最基础的核心容器,二是把XML这些外部配置信息的访问单独剥离出去,现在我们只有XML这一种方式,但是之后还有可能配置到Web或数据库文件里,拆解出去之后也便于扩展。
为了看起来更像Spring,我们以Spring的目录结构为范本,重新构造一下我们的项目代码结构。
com.minis.beans;
com.minis.context;
com.minis.core;
com.minis.test;
定义BeansException
在正式开始解耦工作之前,我们先定义属于我们自己的异常处理类:BeansException。我们来看看异常处理类该如何定义。
public class BeansException extends Exception {
public BeansException(String msg) {
super(msg);
}
}
可以看到,现在的异常处理类比较简单,它是直接调用父类(Exception)处理并抛出异常。有了这个基础的BeansException之后,后续我们可以根据实际情况对这个类进行拓展。
定义 BeanFactory
首先要拆出一个基础的容器来,刚才我们反复提到了 BeanFactory 这个词,现在我们正式引入BeanFactory这个接口,先让这个接口拥有两个特性:一是获取一个Bean(getBean),二是注册一个BeanDefinition(registerBeanDefinition)。你可以看一下它们的定义。
public interface BeanFactory {
Object getBean(String beanName) throws BeansException;
void registerBeanDefinition(BeanDefinition beanDefinition);
}
定义Resource
刚刚我们将BeanFactory的概念进行了抽象定义。接下来我们要定义Resource这个概念,我们把外部的配置信息都当成Resource(资源)来进行抽象,你可以看下相关接口。
public interface Resource extends Iterator<Object> {
}
定义ClassPathXmlResource
目前我们的数据来源比较单一,读取的都是XML文件配置,但是有了Resource这个接口后面我们就可以扩展,从数据库还有Web网络上面拿信息。现在有BeanFactory了,有Resource接口了,拆解这两部分的接口也都有了。接下来就可以来实现了。
现在我们读取并解析XML文件配置是在ClassPathXmlApplicationContext类中完成的,所以我们下一步的解耦工作就是定义ClassPathXmlResource,将解析XML的工作交给它完成。
public class ClassPathXmlResource implements Resource{
Document document;
Element rootElement;
Iterator<Element> elementIterator;
public ClassPathXmlResource(String fileName) {
SAXReader saxReader = new SAXReader();
URL xmlPath = this.getClass().getClassLoader().getResource(fileName);
//将配置文件装载进来,生成一个迭代器,可以用于遍历
try {
this.document = saxReader.read(xmlPath);
this.rootElement = document.getRootElement();
this.elementIterator = this.rootElement.elementIterator();
}
}
public boolean hasNext() {
return this.elementIterator.hasNext();
}
public Object next() {
return this.elementIterator.next();
}
}
操作XML文件格式都是dom4j帮我们做的。
注:dom4j这个外部jar包方便我们读取并解析XML文件内容,将XML的标签以及参数转换成Java的对象。当然我们也可以自行写代码来解析文件,但是为了简化代码,避免重复造轮子,这里我们选择直接引用第三方包。
XmlBeanDefinitionReader
现在我们已经解析好了XML文件,但解析好的XML如何转换成我们需要的BeanDefinition呢?这时XmlBeanDefinitionReader就派上用场了。
public class XmlBeanDefinitionReader {
BeanFactory beanFactory;
public XmlBeanDefinitionReader(BeanFactory beanFactory) {
this.beanFactory = beanFactory;
}
public void loadBeanDefinitions(Resource resource) {
while (resource.hasNext()) {
Element element = (Element) resource.next();
String beanID = element.attributeValue("id");
String beanClassName = element.attributeValue("class");
BeanDefinition beanDefinition = new BeanDefinition(beanID, beanClassName);
this.beanFactory.registerBeanDefinition(beanDefinition);
}
}
}
可以看到,在XmlBeanDefinitionReader中,有一个loadBeanDefinitions方法会把解析的XML内容转换成BeanDefinition,并加载到BeanFactory中。
BeanFactory功能扩展
首先,定义一个简单的BeanFactory实现类SimpleBeanFactory。
public class SimpleBeanFactory implements BeanFactory{
private List<BeanDefinition> beanDefinitions = new ArrayList<>();
private List<String> beanNames = new ArrayList<>();
private Map<String, Object> singletons = new HashMap<>();
public SimpleBeanFactory() {
}
//getBean,容器的核心方法
public Object getBean(String beanName) throws BeansException {
//先尝试直接拿Bean实例
Object singleton = singletons.get(beanName);
//如果此时还没有这个Bean的实例,则获取它的定义来创建实例
if (singleton == null) {
int i = beanNames.indexOf(beanName);
if (i == -1) {
throw new BeansException();
}
else {
//获取Bean的定义
BeanDefinition beanDefinition = beanDefinitions.get(i);
try {
singleton = Class.forName(beanDefinition.getClassName()).newInstance();
}
//注册Bean实例
singletons.put(beanDefinition.getId(), singleton);
}
}
return singleton;
}
public void registerBeanDefinition(BeanDefinition beanDefinition) {
this.beanDefinitions.add(beanDefinition);
this.beanNames.add(beanDefinition.getId());
}
}
由SimpleBeanFactory的实现不难看出,这就是把ClassPathXmlApplicationContext中有关BeanDefinition实例化以及加载到内存中的相关内容提取出来了。提取完之后ClassPathXmlApplicationContext就是一个“空壳子”了,一部分交给了BeanFactory,一部分又交给了Resource和Reader。这时候它又该如何发挥“集成者”的功能呢?我们看看它现在是什么样子的。
public class ClassPathXmlApplicationContext implements BeanFactory{
BeanFactory beanFactory;
//context负责整合容器的启动过程,读外部配置,解析Bean定义,创建BeanFactory
public ClassPathXmlApplicationContext(String fileName) {
Resource resource = new ClassPathXmlResource(fileName);
BeanFactory beanFactory = new SimpleBeanFactory();
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(beanFactory);
reader.loadBeanDefinitions(resource);
this.beanFactory = beanFactory;
}
//context再对外提供一个getBean,底下就是调用的BeanFactory对应的方法
public Object getBean(String beanName) throws BeansException {
return this.beanFactory.getBean(beanName);
}
public void registerBeanDefinition(BeanDefinition beanDefinition) {
this.beanFactory.registerBeanDefinition(beanDefinition);
}
}
可以看到,当前的ClassPathXmlApplicationContext在实例化的过程中做了三件事。
- 解析XML文件中的内容。
- 加载解析的内容,构建BeanDefinition。
- 读取BeanDefinition的配置信息,实例化Bean,然后把它注入到BeanFactory容器中。
通过上面几个步骤,我们把XML中的配置转换成Bean对象,并把它交由BeanFactory容器去管理,这些功能都实现了。虽然功能与原始版本相比没有发生任何变化,但这种 一个类只做一件事的思想 是值得我们在编写代码的过程中借鉴的。
小结
好了,这节课就讲到这里。通过简简单单几个类,我们就初步构建起了MiniSpring的核心部分:Bean和IoC。
可以看到,通过这节课的构建,我们在业务程序中不需要再手动new一个业务类,只要把它交由框架容器去管理就可以获取我们所需的对象。另外还支持了Resource和BeanFactory,用Resource定义Bean的数据来源,让BeanFactory负责Bean的容器化管理。通过功能解耦,容器的结构会更加清晰明了,我们阅读起来也更加方便。当然最重要的是,这可以方便我们今后对容器进行扩展,适配更多的场景。
以前看似高深的Spring核心概念之一的IoC,就这样被我们拆解成了最简单的概念。它虽然原始,但已经具备了基本的功能,是一颗可以生长发育的种子。我们后面把其他功能一步步添加上去,这个可用的小种子就能发育成一棵大树。
完整源代码参见 https://github.com/YaleGuo/minis
课后题
学完这节课,我也给你留一道思考题。IoC的字面含义是“控制反转”,那么它究竟“反转”了什么?又是怎么体现在代码中的?欢迎你在留言区与我交流讨论,也欢迎你把这节课分享给需要的朋友。我们下节课见!